
Fundamentos del Machine Learning: Guía Completa para Iniciar en el Aprendizaje Automático
Introducción
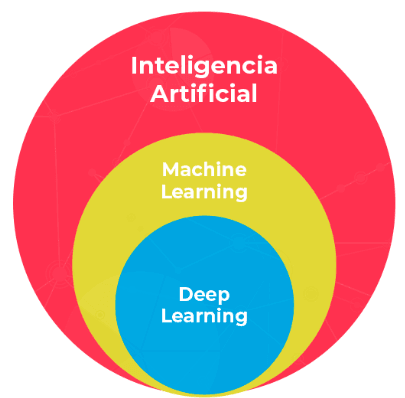
Antes de adentrarnos en los detalles del Machine Learning (ML), es crucial entender que ML es una rama de la Inteligencia Artificial (IA). A menudo, se confunden ambos términos, pero mientras que la IA abarca un amplio campo que busca replicar la inteligencia humana, el ML se centra específicamente en desarrollar algoritmos que permitan a las máquinas aprender de los datos y tomar decisiones sin intervención humana explícita.
En este blog, explicaremos paso a paso cómo funciona el Machine Learning, desde la captura inicial de datos hasta la implementación de modelos en producción. Este conocimiento es fundamental para entender cómo las organizaciones pueden automatizar tareas complejas y tomar decisiones basadas en datos.
Machine Learning vs. Deep Learning
- Machine Learning (ML): El Machine Learning es una rama de la Inteligencia Artificial que se centra en el desarrollo de algoritmos y modelos que aprenden patrones a partir de datos y hacen predicciones o decisiones sin intervención humana explícita. Los modelos de ML pueden ser supervisados, no supervisados o por refuerzo, dependiendo de la forma en que aprenden de los datos.
- Deep Learning: El Deep Learning es una subárea del Machine Learning que utiliza redes neuronales profundas para aprender representaciones jerárquicas de datos. Es especialmente útil para problemas complejos de procesamiento de imágenes, sonido y texto, donde los patrones son difíciles de capturar con métodos tradicionales de ML.
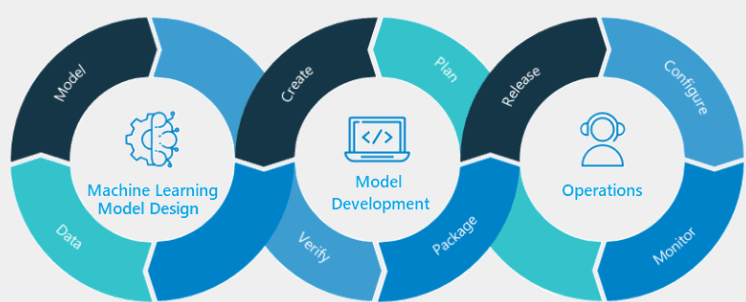
Ahora, si queremos construir una solución que funcione correctamente, debemos seguir siempre los siguientes pasos:
1. Proceso de ETL en Machine Learning
Para construir una solución efectiva en Machine Learning, es fundamental seguir un proceso estructurado de Extracción, Transformación y Carga (ETL). Este proceso asegura que los datos estén correctamente preparados antes de aplicar modelos de ML, maximizando la precisión y relevancia de las predicciones.
El proceso ETL es crucial porque garantiza que los datos estén limpios, estructurados y listos para su análisis. Aquí explicamos cada paso del proceso:
1.1 Captura/Extracción de datos: La captura de datos es el primer paso crítico en el proceso de Machine Learning. Sin datos de calidad y adecuadamente estructurados, cualquier modelo que se construya puede carecer de precisión y relevancia. Aquí se exploran los métodos y consideraciones clave para adquirir datos confiables.
- Los datos son el combustible del Machine Learning. Cada decisión tomada por un modelo ML se basa en los datos con los que fue entrenado y probado. Por lo tanto, la calidad y cantidad de los datos son fundamentales para la precisión y generalización del modelo.
- Los datos pueden provenir de diversas fuentes, como bases de datos transaccionales, registros de eventos, archivos CSV, APIs web, sensores IoT, entre otros. Es crucial seleccionar fuentes que sean relevantes y completas para el problema a resolver.
1.2 Transformación de los datos: Una vez que los datos están capturados, es necesario transformarlos para prepararlos adecuadamente para el análisis. La transformación incluye:
- Limpieza de Datos: Eliminar valores nulos, corregir errores y estandarizar formatos para asegurar la coherencia y calidad de los datos.
- Normalización y Estandarización: Ajustar los datos para que estén en una escala uniforme, lo que facilita el análisis y mejora el rendimiento de los modelos.
- Feature Engineering: Crear nuevas variables o características a partir de los datos existentes para mejorar la capacidad predictiva del modelo.
1.3 Carga de los datos: Una vez que los datos están transformados, se cargan en un formato adecuado para su uso en modelos de Machine Learning. Este proceso implica:
- Integración con Plataformas de ML: Asegurar que los datos preparados estén integrados correctamente con las plataformas y herramientas de ML utilizadas para construir y entrenar modelos.
- Validación de Datos: Verificar la integridad y consistencia de los datos cargados para evitar errores durante el análisis y modelado.
Es importante entender que el éxito del proceso ETL en Machine Learning no solo depende de la tecnología utilizada, sino también de la comprensión profunda del dominio del problema y de los datos.
2. Selección del Modelo:
Una vez que los datos han sido capturados, transformados y cargados correctamente, el siguiente paso crítico en el proceso de Machine Learning es la selección del modelo adecuado. La elección del modelo depende del tipo de problema que estemos tratando de resolver y de la naturaleza de los datos disponibles.2.1 Tipos de Aprendizaje en Machine LearningEl Machine Learning se subdivide en diferentes tipos de aprendizaje, cada uno adecuado para diferentes tareas y tipos de datos:
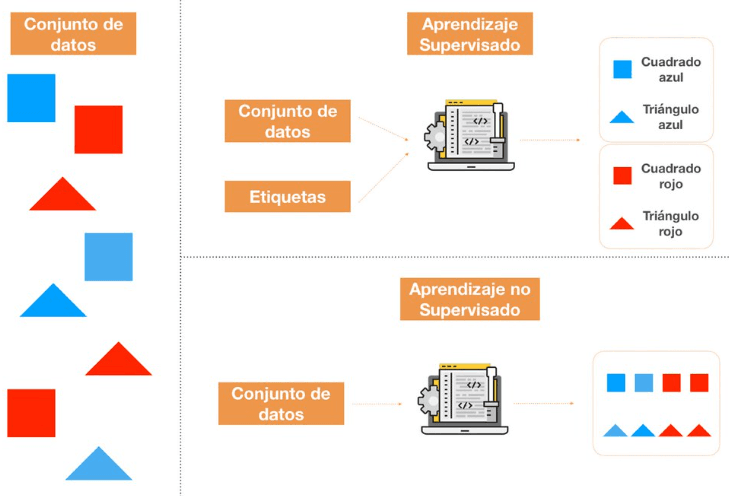
2.1 Aprendizaje Supervisado: En el aprendizaje supervisado, los modelos aprenden a partir de datos etiquetados que contienen la respuesta correcta. Por ejemplo, en la clasificación de imágenes, se proporcionan imágenes etiquetadas como "perro" o "gato", y el modelo aprende a predecir la etiqueta correcta para nuevas imágenes. Algunos tipos comunes de modelos de aprendizaje supervisado incluyen:
Regresión Lineal:
- Uso: Predice valores numéricos continuos basados en variables independientes.
- Explicación: Adecuado cuando se quiere establecer una relación lineal entre variables, por ejemplo, predecir el precio de una casa basado en características como el tamaño o la ubicación.
Regresión Logística:
- Uso: Clasificación binaria, predice la probabilidad de que una observación pertenezca a una clase.
- Explicación: Ideal para problemas donde se necesita predecir eventos, como si un correo electrónico es spam o no, basado en características como palabras clave y características del correo.
Árboles de Decisión:
- Uso: Clasificación o regresión, divide los datos en subconjuntos basados en características para hacer predicciones.
- Explicación: Útil cuando se quiere entender cómo se toman decisiones basadas en características específicas, como predecir el riesgo de crédito basado en ingresos, historial crediticio, etc.
Random Forest:
- Uso: Mejora de árboles de decisión, utiliza múltiples árboles para mejorar la precisión y evitar el sobreajuste.
- Explicación: Adecuado cuando se necesita una predicción robusta y precisa, combinando la predicción de varios árboles para reducir el riesgo de errores debido al sesgo o la variabilidad de datos.
Máquinas de Vectores de Soporte (SVM):
- Uso: Clasificación o regresión, encuentra el hiperplano óptimo que mejor separa las clases.
- Explicación: Ideal cuando se necesita encontrar una frontera de decisión clara entre clases en datos de alta dimensionalidad, como clasificar imágenes o datos de texto.
Cada tipo de modelo tiene sus ventajas y desventajas, y la elección del modelo adecuado depende del problema específico que estés tratando de resolver, la naturaleza de tus datos y tus objetivos de predicción.
2.2 Aprendizaje No Supervisado: En el aprendizaje no supervisado, los modelos se utilizan principalmente para descubrir patrones ocultos o estructuras dentro de los datos sin etiquetas explícitas. Aquí tienes algunos tipos comunes de modelos no supervisados y sus aplicaciones:
Agrupamiento (Clustering):
- Uso: Agrupación de datos similares en conjuntos discretos.
- Explicación: Algoritmos como k-means, DBSCAN, y clustering jerárquico permiten identificar grupos naturales dentro de los datos sin etiquetas, como segmentar clientes según comportamientos de compra o agrupar documentos según temas.
Análisis de Asociación:
- Uso: Identificación de patrones frecuentes o asociaciones entre variables.
- Explicación: Aplicado en minería de datos para descubrir relaciones entre elementos, como en la recomendación de productos basada en la compra histórica de usuarios.
Reducción de Dimensionalidad:
- Uso: Simplificación de datos conservando la mayor cantidad de información posible.
- Explicación: Métodos como t-SNE o MDS son útiles para visualizar datos complejos en espacios de menor dimensión, preservando relaciones importantes entre puntos.
Detección de Anomalías:
- Uso: Identificación de observaciones inusuales o outliers en los datos.
- Explicación: Importante en la detección de fraudes, mantenimiento predictivo o cualquier caso donde datos anómalos puedan indicar problemas o comportamientos no esperados.
Descomposición de Matrices:
- Uso: Factorización de matrices para identificar estructuras latentes.
- Explicación: Se utiliza en sistemas de recomendación y análisis de redes sociales para descubrir patrones subyacentes en grandes conjuntos de datos matriciales.
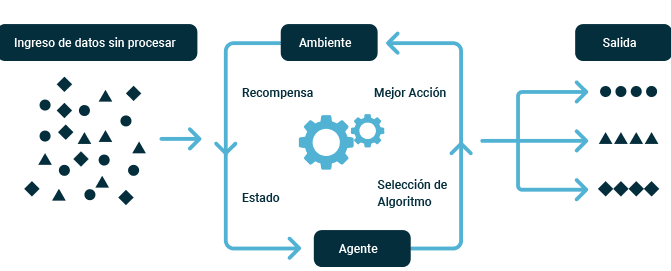
2.3 Aprendizaje por Refuerzo: En el aprendizaje por refuerzo, los agentes aprenden a través de prueba y error, recibiendo recompensas o castigos según sus acciones. Esto se utiliza en aplicaciones como juegos y robótica, donde los agentes aprenden a través de la interacción con el entorno. Aqui algunos modelos:
Q-Learning:
- Uso: Aprendizaje de políticas óptimas en entornos discretos.
- Explicación: El agente aprende a tomar decisiones secuenciales maximizando la recompensa acumulada a través de la actualización iterativa de la función Q, que estima el valor esperado de tomar una acción en un estado específico.
Exploración vs. Explotación:
- Uso: Balanceo entre tomar decisiones conocidas y explorar nuevas acciones para descubrir mejores políticas.
- Explicación: Es crucial en el aprendizaje por refuerzo para evitar quedarse atrapado en políticas subóptimas y descubrir acciones que puedan llevar a mayores recompensas a largo plazo.
3. Evaluación del Modelo
Una vez que se ha seleccionado y entrenado un modelo de Machine Learning, es fundamental evaluar su rendimiento antes de implementarlo en producción. La evaluación proporciona información crucial sobre la capacidad del modelo para generalizar a nuevos datos y su precisión en la tarea específica para la que fue diseñado. En esta sección, exploramos diferentes técnicas y métricas utilizadas para evaluar modelos de Machine Learning.
3.1 Métricas de Evaluación
- Matriz de Confusión: La matriz de confusión es una herramienta fundamental para evaluar el rendimiento de un modelo de clasificación. Permite visualizar la cantidad de predicciones correctas e incorrectas en cada clase, lo que facilita la identificación de errores como falsos positivos y falsos negativos.
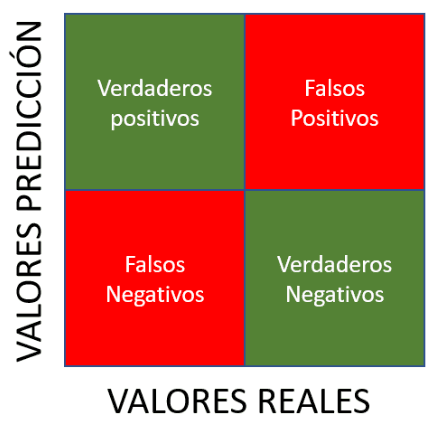
- Precisión, Recall y F1-Score: Estas métricas son comunes en problemas de clasificación y proporcionan una comprensión detallada del rendimiento del modelo en términos de precisión (cuántas predicciones positivas son correctas), recall (cuántas de las verdaderas positivas detectó el modelo) y F1-score (una medida combinada de precisión y recall).
- Curva ROC y Área bajo la Curva (AUC-ROC): La curva ROC (Receiver Operating Characteristic) es útil para evaluar modelos de clasificación binaria, mostrando la relación entre la tasa de verdaderos positivos y la tasa de falsos positivos a través de diferentes umbrales de decisión. El AUC-ROC proporciona una medida agregada del rendimiento del modelo.
3.2 Optimización de Hiperparámetros
- Los hiperparámetros son configuraciones ajustables que no se aprenden directamente del proceso de entrenamiento del modelo. Optimizar estos hiperparámetros puede mejorar significativamente el rendimiento del modelo. Técnicas comunes incluyen la búsqueda exhaustiva (Grid Search) y la búsqueda aleatoria (Random Search) para encontrar la combinación óptima de hiperparámetros.
3.3 Validación Cruzada (Cross-Validation)
- La validación cruzada es una técnica para evaluar el rendimiento de un modelo utilizando múltiples subconjuntos de datos de entrenamiento y prueba. Esto ayuda a mitigar el riesgo de sobreajuste y proporciona una evaluación más robusta del rendimiento del modelo en datos no vistos.
3.4 Interpretación de Resultados
- Es crucial interpretar los resultados de las métricas de evaluación y las visualizaciones obtenidas durante el proceso de evaluación del modelo. Esto permite ajustar el modelo si es necesario, comprender sus fortalezas y debilidades, y tomar decisiones informadas sobre su implementación y mejora continua.
4. Puesta en Producción del Modelo
Una vez que se ha entrenado y evaluado un modelo de Machine Learning con buen rendimiento, el siguiente paso crucial es implementarlo en un entorno de producción para su uso en aplicaciones reales. Esta fase implica varios procesos y consideraciones para asegurar que el modelo funcione de manera efectiva, eficiente y escalable.
4.1 Preparación para la Implementación
- Optimización y Compactación del Modelo: Antes de la implementación, es común optimizar el modelo para reducir su tamaño y complejidad, lo que mejora la eficiencia computacional y acelera las inferencias. Técnicas como la cuantización de modelos y la poda de pesos pueden ser utilizadas para este propósito.
- Integración con Infraestructura Existente: El modelo debe integrarse con la infraestructura de software y hardware existente en el entorno de producción. Esto puede incluir sistemas de gestión de bases de datos, APIs para la comunicación con otras aplicaciones, y servicios de almacenamiento y procesamiento de datos.
4.2 Gestión de Versiones y Control de Calidad
- Gestión de Versiones: Es crucial implementar un sistema robusto de gestión de versiones para rastrear cambios en el modelo y asegurar que las actualizaciones se desplieguen de manera controlada y reversible. Herramientas como Git y controladores específicos de modelos pueden ser utilizados para este fin.
- Pruebas y Validación en Entorno de Producción: Antes de lanzar el modelo en producción, se deben realizar pruebas exhaustivas para asegurar que funcione correctamente en diferentes escenarios y condiciones de carga. La validación cruzada y las pruebas de estrés son útiles para identificar posibles problemas y optimizar el rendimiento.
4.3 Monitoreo y Mantenimiento Continuo
- Monitoreo del Rendimiento: Una vez en producción, es crucial monitorear continuamente el rendimiento del modelo para detectar desviaciones en la precisión o eficiencia. Esto puede implicar el monitoreo de métricas de rendimiento en tiempo real y la configuración de alertas automáticas para problemas potenciales.
- Mantenimiento y Actualización: Los modelos de Machine Learning son dinámicos y pueden requerir ajustes periódicos para mantener su precisión y relevancia. El mantenimiento incluye la actualización de datos de entrenamiento, el reentrenamiento del modelo con nuevos datos y la optimización de hiperparámetros según sea necesario.
4.4 Escalabilidad y Seguridad
- Escalabilidad: El diseño de la arquitectura de implementación debe considerar la capacidad de escalar el modelo para manejar un aumento en la carga de trabajo o la expansión del alcance del sistema. El uso de contenedores como Docker y la implementación en plataformas de escalado automático como Kubernetes son prácticas comunes.
- Seguridad: La seguridad de los modelos en producción es crucial para proteger los datos sensibles y asegurar la integridad del sistema. Esto puede incluir prácticas como el cifrado de datos, la gestión de accesos y la implementación de medidas de seguridad en las API y puntos de acceso al modelo.
La puesta en producción de un modelo de Machine Learning es un proceso complejo que requiere cuidadosa planificación y ejecución. Siguiendo las mejores prácticas y considerando las necesidades específicas del entorno, se asegura que el modelo pueda generar valor de manera efectiva y sostenible en el mundo real.
Glosario:
Sesgo:
- En Machine Learning, el sesgo se refiere a la diferencia entre la predicción del modelo y el valor verdadero que se intenta predecir. Un sesgo alto indica que el modelo no puede capturar la relación subyacente entre los datos, lo que puede llevar a predicciones inexactas y no generalizables.
Hiperplano:
- Un hiperplano es una generalización del concepto de plano o línea en espacios de dimensiones superiores. En Machine Learning, especialmente en algoritmos de clasificación como las Máquinas de Vectores de Soporte (SVM), un hiperplano es utilizado como una frontera de decisión que separa clases distintas en el espacio de características.
Clustering:
- Clustering es el proceso de agrupar un conjunto de objetos de tal manera que objetos en el mismo grupo (o cluster) son más similares entre sí que con los de otros grupos. Es un método común en el aprendizaje no supervisado para explorar patrones y estructuras ocultas en los datos.
K-means:
- K-means es un algoritmo de clustering que agrupa datos en K grupos basados en sus características. Funciona asignando puntos de datos al grupo cuyo centroide (punto medio) está más cercano a ellos, optimizando iterativamente la posición de los centroides hasta converger en una solución.
DBSCAN:
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) es un algoritmo de clustering que agrupa puntos de datos en clusters basados en la densidad local de los puntos. Es capaz de identificar clusters de formas arbitrarias y manejar eficientemente datos con ruido y outliers.
t-SNE (t-Distributed Stochastic Neighbor Embedding):
- t-SNE es una técnica de reducción de dimensionalidad no lineal utilizada principalmente para la visualización de conjuntos de datos de alta dimensionalidad. Se enfoca en preservar las relaciones locales entre puntos de datos, lo que permite revelar estructuras complejas en los datos en un espacio de menor dimensión.
MDS (Multidimensional Scaling):
- MDS es una técnica de análisis estadístico utilizada para visualizar la similitud entre objetos. Transforma las similitudes entre puntos de datos en distancias en un espacio de menor dimensión, preservando las relaciones entre ellos tanto como sea posible.
Agente:
- En el contexto del aprendizaje por refuerzo, un agente es una entidad que interactúa con un entorno con el objetivo de maximizar una recompensa acumulada a lo largo del tiempo. El agente toma decisiones basadas en su política de acción aprendida y las observaciones del entorno.
Cuantización:
- En el contexto de redes neuronales o análisis de datos, la cuantización se refiere al proceso de reducir el número de valores distintos de una variable. Puede implicar la reducción de la precisión numérica para simplificar cálculos o el agrupamiento de valores similares para simplificar modelos.
Poda:
- En el contexto de árboles de decisión y otros modelos basados en árboles, la poda se refiere al proceso de eliminar secciones no deseadas o irrelevantes de un árbol para mejorar su precisión y capacidad de generalización. La poda puede ser pre-poda (antes de la construcción completa del árbol) o post-poda (después de la construcción).
Grid Search:
- Grid Search es una técnica para encontrar los mejores hiperparámetros para un modelo de Machine Learning. Evalúa exhaustivamente las combinaciones de hiperparámetros especificadas en una cuadrícula predefinida, utilizando validación cruzada para determinar qué combinación proporciona el mejor rendimiento.
Random Search:
- Random Search es una estrategia para la optimización de hiperparámetros que selecciona combinaciones aleatorias de hiperparámetros para evaluar el rendimiento del modelo. A diferencia de Grid Search, no evalúa todas las combinaciones posibles, lo que puede ser más eficiente computacionalmente en espacios de búsqueda grandes o complejos.
¿Listo para implementar soluciones de Machine Learning en tus proyectos?
En Kranio, contamos con expertos en inteligencia artificial que te ayudarán a desarrollar e implementar modelos de Machine Learning adaptados a las necesidades de tu negocio. Contáctanos y descubre cómo podemos impulsar la transformación digital de tu empresa mediante el aprendizaje automático.
Entradas anteriores

Augmented Coding vs Vibe Coding
La IA genera código funcional, pero no garantiza seguridad. Aprende a usarla con criterio para construir software robusto, escalable y sin riesgos.

Kranear también es proteger: el proceso detrás de nuestra certificación ISO 27001
A finales de 2025, Kranio obtuvo la certificación ISO 27001 tras implementar su Sistema de Gestión de Seguridad de la Información (SGSI). Este proceso no fue solo un ejercicio de cumplimiento, sino una decisión estratégica para fortalecer cómo diseñamos, construimos y operamos sistemas digitales. En este artículo compartimos el proceso, los cambios internos que implicó y el impacto que tiene para nuestros clientes: mayor control, gestión estructurada de riesgos y una base más sólida para escalar sistemas con confianza.
