Transformación de Datos en ETL para Machine Learning: Guía Práctica con Pandas y Técnicas Avanzadas
Transformación de Datos en ETL
La transformación de datos es el segundo paso crucial en el proceso de Extracción, Transformación y Carga (ETL), que juega un papel fundamental en la preparación de los datos para el análisis avanzado y el modelado de Machine Learning. Este paso implica una serie de operaciones diseñadas para convertir datos crudos en un formato más adecuado y útil para el análisis específico que se necesita realizar. Vamos a explorar a detalle las transformaciones básicas y avanzadas utilizando Pandas, la normalización y estructuración de datos, la limpieza y manipulación de texto, el feature engineering, el manejo de datos categóricos, y las técnicas de validación de datos.
Transformaciones Básicas y Avanzadas con Pandas
Pandas es una herramienta poderosa en Python para la manipulación de datos debido a su capacidad para manejar de forma eficiente estructuras de datos complejas.
Transformaciones Básicas con Pandas
Las operaciones básicas en Pandas son fundamentales para la manipulación de datos diaria y pueden incluir selección de columnas, filtrado de filas y ordenamiento de datos.
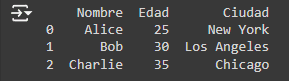
- Selección de Columnas: Para seleccionar una columna específica de un DataFrame, simplemente puedes usar el nombre de la columna entre corchetes.
Output:
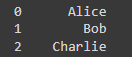
2. Filtrado de Filas: Puedes filtrar filas basadas en condiciones lógicas. Por ejemplo, para seleccionar todas las filas donde la edad es mayor que 28:
Output:
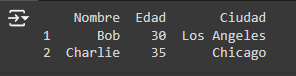
3. Ordenamiento de Datos: Para ordenar los datos por una columna, puedes usar sort_values(). Por ejemplo, ordenar por 'Edad':
Output:
Transformaciones Avanzadas con Pandas
Las operaciones avanzadas permiten realizar transformaciones más complejas y son particularmente útiles para preparar datos para análisis estadísticos o de Machine Learning.
- Agrupaciones y Agregaciones: Agrupar datos según una o más columnas y luego aplicar funciones de agregación como suma, promedio, máximo, etc.
Output:
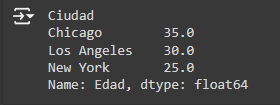
2. Transformaciones Condicionales: Aplicar transformaciones basadas en condiciones. Por ejemplo, aumentar la edad en 1 año sólo para aquellos en 'New York'.
Output:
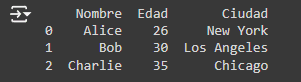
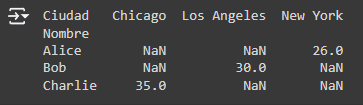
3. Pivot Tables: Las tablas pivote son útiles para resumir un conjunto de datos. Por ejemplo, crear una tabla pivote que muestre el promedio de edad por ciudad y nombre.
Output:
Normalización y Estructuración de Datos
La normalización y estructuración de datos son dos procesos fundamentales en el tratamiento de los datos para análisis y modelado, especialmente en el contexto de proyectos de Machine Learning y análisis de datos avanzados.
Normalización de Datos
La normalización es un método para escalar los datos numéricos en un rango específico o según una distribución particular, lo que facilita la comparación y el análisis de diferentes características que pueden tener escalas o unidades distintas. Hay varios métodos de normalización, cada uno con sus propios casos de uso:
- Min-Max Scaling:some text
- Descripción: Este método escala los datos para que estén dentro de un rango específico, generalmente 0 a 1, o -1 a 1 si hay valores negativos.
- Fórmula:
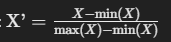
- Uso: Útil cuando necesitas un rango numérico estricto para tu modelo y cuando no estás preocupado por los valores atípicos que pueden distorsionar la reescala de los datos.
- Z-score Standardization (Standard Scaler):some text
- Descripción: Consiste en reescalar los datos para que tengan una media de 0 y una desviación estándar de 1.
- Fórmula:
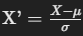
- Uso: Especialmente útil cuando los datos tienen una distribución normal, y es más robusto frente a valores atípicos en comparación con el escalado min-max.
Ejemplo:
Output:
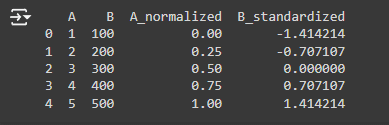
Aquí, min(A)=1 y max(A)=5. Aplicando la fórmula a cada valor:
- Para A=1: (1−1)/(5−1)=0.00
- Para A=2: (2−1)/(5−1)=0.25
- Para A=3: (3−1)/(5−1)=0.50
- Para A=4: (4−1)/(5−1)=0.75
- Para A=5: (5−1)/(5−1)=1.00}
Y así aplicando la otra formula
Estructuración de Datos
La estructuración de datos se refiere al proceso de organizar y formatear los datos de manera que sean fácilmente accesibles y analizables. Esto puede incluir la reorganización de los datos en nuevas estructuras, la consolidación de fuentes de datos, y la transformación de datos no estructurados en formatos estructurados.
- Reestructuración de DataFrames:some text
- Operaciones: Pueden incluir pivoteo de tablas y unión de múltiples fuentes de datos.
- Herramientas: Pandas ofrece funciones como pivot_table, merge, y concat para facilitar estos procesos.
- Conversión de Formatos de Datos:some text
- Descripción: Convertir datos de formatos semi-estructurados o no estructurados (como JSON, XML) a estructuras tabulares (DataFrames).
- Implementación: Utilizar parsers específicos de Python para leer estos formatos y cargarlos en Pandas.
Ejemplo:
Output:
Limpieza y Manipulación de Texto
1. Eliminación de caracteres especiales y números Muchos textos incluyen caracteres que no son relevantes para el análisis, como símbolos especiales, números y puntuación. La eliminación de estos caracteres puede hacer que el texto sea más uniforme y fácil de analizar.
Output:

2. Conversión a minúsculas Convertir todo el texto a minúsculas es un paso fundamental para estandarizar los datos y evitar que las mismas palabras sean interpretadas como diferentes debido a diferencias en mayúsculas y minúsculas.
Output:
3. Eliminación de espacios extra Es común encontrar espacios adicionales que deben eliminarse para mantener la consistencia.
4. Tokenización La tokenización es el proceso de dividir el texto en unidades más pequeñas, como palabras o frases. Esto es útil para técnicas de análisis de texto más detalladas, como el conteo de palabras o la vectorización.
Output:
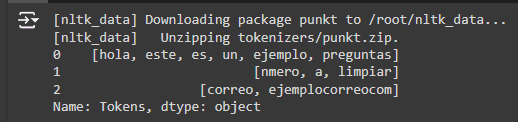
5. Eliminación de stopwords Las stopwords son palabras que no aportan significado al texto y pueden ser eliminadas. Ejemplos comunes en español incluyen 'y', 'que', 'de', etc.
Output:
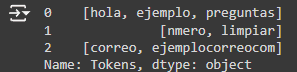
Estos pasos y técnicas ayudarán a preparar los datos de texto para análisis más complejos y modelos de machine learning, asegurando que el texto esté limpio y estandarizado.
Ahora bien, el Feature Engineering, o ingeniería de características, es una parte fundamental de la etapa de transformación en los procesos ETL, especialmente cuando se preparan datos para modelos de Machine Learning. Aquí, transformas y creas características que ayudan a mejorar el rendimiento de los modelos predictivos.
Feature Engineering
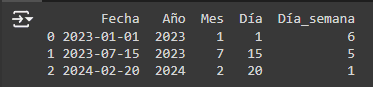
1. Creación de características a partir de fechas Las fechas pueden descomponerse en múltiples características como año, mes, día, día de la semana, etc., lo cual puede ser útil para capturar patrones estacionales o tendencias a lo largo del tiempo.
Output:
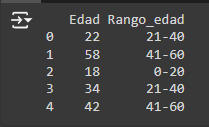
2. Binning de datos numéricos: Consiste en convertir variables numéricas continuas en categorías discretas, lo cual puede ser útil para modelos que trabajan mejor con características categóricas.
Output:
3. Características categóricas basadas en condiciones: Podemos crear nuevas características categóricas aplicando reglas específicas o condiciones lógicas sobre los datos existentes.
Output:
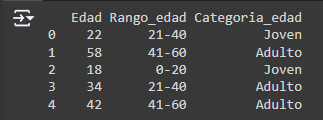
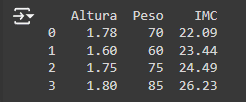
4. Interacciones entre características: Crear nuevas características a través de la interacción de características existentes puede revelar relaciones que no son evidentes de otro modo.
Output:
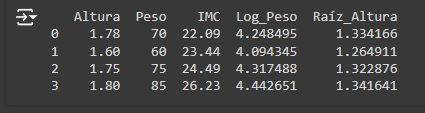
5. Transformaciones logarítmicas y de raíz cuadrada Las transformaciones logarítmicas y de raíz cuadrada son útiles para reducir la asimetría de las distribuciones de datos.
Output:
6. Codificación de variables categóricas (Encoding) Convertir variables categóricas en formatos numéricos es esencial para muchos algoritmos de machine learning.
Output:
Manejo de Datos Categóricos
1. Codificación de etiquetas (Label Encoding) La codificación de etiquetas transforma cada categoría en un número. Es útil cuando las categorías tienen un orden natural (ordinal), pero su uso indiscriminado puede implicar una relación de orden donde no existe, potencialmente llevando a interpretaciones erróneas por parte de los modelos.
Output:
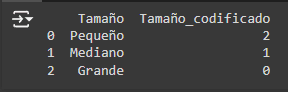
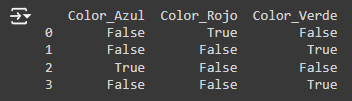
2. Codificación One-hot (One-Hot Encoding) La codificación One-hot convierte cada categoría en una nueva columna y asigna un 1 ó 0 (Verdadero/Falso). Es ideal para variables nominales sin un orden inherente.
Output:
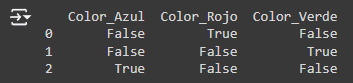
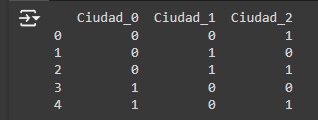
3. Codificación binaria Transforma las categorías en binario y luego las descompone en columnas individuales. Es más eficiente que One-hot en términos de espacio, especialmente para categorías con muchos niveles.
Output:
Cada uno de estos métodos tiene sus ventajas y limitaciones, y la elección depende del contexto específico del problema y de los requisitos del modelo de Machine Learning a utilizar. Es importante probar diferentes enfoques y seleccionar el que mejor preserve la información relevante y contribuya al rendimiento del modelo.
Para finalizar, es crucial realizar validación de datos para garantizar la calidad y la fiabilidad de los datos en los procesos ETL, ayudando a detectar y corregir errores antes de que los datos sean utilizados para análisis o modelado.
Técnicas de Validación de Datos
1. Validación de Rangos (Range Checking): Esta técnica implica verificar que los valores de datos estén dentro de un rango específico definido por reglas de negocio o lógica de dominio. Por ejemplo, la edad en una encuesta no debería ser negativa ni irrealmente alta.
2. Validación de Integridad Referencial: Esta técnica se asegura de que los identificadores o claves en una tabla corresponden correctamente a los de otras tablas, manteniendo la consistencia de los datos entre diferentes partes de la base de datos.
3. Validación de Formatos (Format Checking): Consiste en asegurar que los datos textuales cumplan con formatos específicos, como códigos postales, números de teléfono, direcciones de correo electrónico, entre otros.
4. Validación de Unicidad (Uniqueness Checking): Esta técnica verifica que no haya duplicados en datos que deben ser únicos, como identificadores de usuario o números de serie.
5. Validación de Completeness (Completitud): Verifica que no falten valores en los conjuntos de datos, especialmente en las columnas que son esenciales para el análisis o la toma de decisiones.
6. Validación de Consistencia: Asegura que los datos en diferentes campos sean consistentes entre sí, basándose en reglas lógicas o de negocio.
En conclusión, la transformación de datos es una fase crítica dentro del proceso ETL que prepara el terreno para análisis y decisiones informadas.
Implementar estas técnicas correctamente asegura que los datos sean no solo precisos y coherentes, sino también relevantes para los requisitos específicos del negocio o del análisis a realizar. La limpieza de datos, la normalización, la estructuración adecuada, y la validación son pasos esenciales que, aunque a menudo subestimados, tienen un impacto directo en la calidad del insight que se puede derivar de los datos.
Además, la etapa de transformación no solo es sobre manipular datos para que se ajusten a un formato utilizable, sino también sobre agregar valor a través de la ingeniería de características, donde la creatividad y el conocimiento específico del dominio juegan un papel crucial.
Finalmente, es fundamental desarrollar un flujo de trabajo de transformación de datos que sea tanto robusto como flexible, permitiendo ajustes y mejoras continuas a medida que cambian los requerimientos del negocio y la tecnología avanza. Esto garantiza que la infraestructura de datos de una organización no solo sea sostenible, sino que también se mantenga competitiva y relevante.
Parte 1: Introducción al Proceso de ETL en Machine Learning
¿Listo para optimizar la transformación de datos en tus proyectos de Machine Learning?
En Kranio, contamos con expertos en ingeniería de datos y Machine Learning que te ayudarán a implementar procesos ETL eficientes, asegurando que tus modelos se entrenen con datos limpios y estructurados. Contáctanos y descubre cómo podemos potenciar tus proyectos de inteligencia artificial.
Entradas anteriores

Estándares de desarrollo: el sistema operativo invisible que permite escalar sin quemar al equipo
Descubre cómo los estándares de desarrollo reducen bugs, aceleran el onboarding y permiten escalar equipos de ingeniería sin generar fricción.

Autenticación segura en PWAs: mejores prácticas y métodos
Aprende cómo implementar autenticación segura en PWAs usando OAuth 2.0, JWT y MFA para proteger usuarios y evitar vulnerabilidades críticas.
